
Not everything in life is nicely binary, much as we[1] might like it to be. There are shades of grey[2] in many aspects of life, and though humans can often cope with uncertainty, computer systems are less good at it: they generally want a “yes” or “no” answer. This means that decisions sometimes need to be made on incomplete evidence, and, well, that means that the answers aren’t always correct. There’s a whole area of computer science related to this: fuzzy logic.
Let’s look into what the options are. Assuming that we’re looking two options: “yes” (a positive) and “no” (a negative). That means that there are two ways in which the answer can be incorrect:
- a “yes” answer was incorrectly chosen (false positive);
- a “no” answer was incorrectly chosen (false negative).
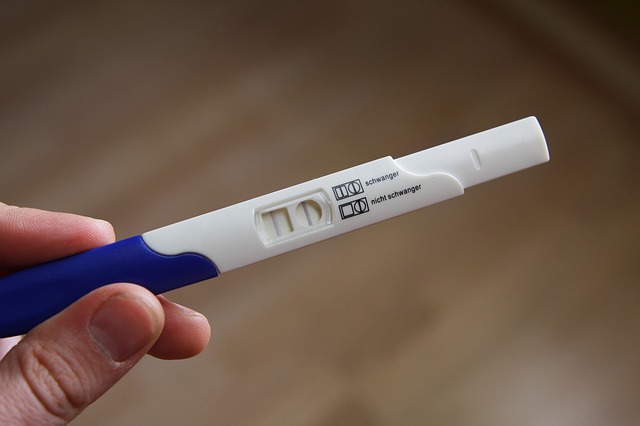
An example to allow us to explore this is pregnancy. It’s generally agreed that you can’t be a little bit pregnant: if you take a test, any result it gives you needs to be either positive or negative. If you are pregnant, and a test result comes back negative, then that’s a false negative. If you are not pregnant, and a test comes back positive, that’s a false positive. The implications of a false positive or a false negative can both be pretty major – as anybody who has received one will tell you. I spent a little time online trying to find expected false positive and false negatives for pregnancy tests, but it turns out that the rates are so dependent on a variety of factors that it was difficult to find a sensible answer[3].
A tragic recent example of a false positive took place on Wednesday, 8th January 2020, when a Ukrainian International Airlines flight was shot down by an Iranian missile, killing all 176 people on board. It appears that an air defence radar system misidentified the aircraft as a cruise missile. As the radar system was looking for a positive identification of a threat, this can be counted as a false positive.
What might have been the alternative in this case? If the aircraft actually had been a cruise missile, but was identified as a civilian aircraft, this would have been a false negative, and the impact might well have been significant damage to an Iranian military installation.
Which is the most damaging? Well, in the case of the aircraft, it would seem pretty clear to most observers that the false positive would be worse, but from a military point of view, that might not be the case. Maybe the impact of a missile strike on a major military installation might be considered worse than the civilian loss of life in the other case. In this case, as in many others, a decision needs to be made as to which is most important to reduce: the chance of a false negative or the chance of a false positive? In a perfect world, of course, there would be no false results, negative or positive. The problem with many systems that take analogue[4] inputs and turn them into digital outputs in this way is that avoiding false results is very costly, and sometimes impossible. Even worse news is that reducing probability of one of the two types of false result tends to increase the probability of the other.
A classic example of this is in the use of biometrics for user identification. Fingerprints, facial recognition, iris scanning and similar techniques have to balance the likelihood of a false positive with a false negative. Which is worse: the chance that the CEO will not be able to update the payroll details, or that a rogue employee will update her details to improve her salary package?[5]
One good piece of news is that AI/ML (Artificial Intelligence/Machine Learning) is improving the performance of biometric systems and, in fact, other areas of computing where “fuzzy logic” is required. In most cases, humans are still better at reducing messy sets of information to yes/no results, but that is changing, and where multiple automated decisions need to be made, then AI/ML is worth considering.
Whenever you are dealing with “messy” data[6] which needs to be reduced to a “yes/no” or “positive/negative” binary result, you need to consider the likelihood of false positives or negatives. Not only do you need to consider the likelihood of each, but also the impact of each. Once you have understood these, you can then decide which you want to try to minimise, and what techniques you should use to do so.
We may be stuck with false results, but we need to understand what our choices are, and how we can get the best outcomes available from messy data.
1 – in talking security, but I’m sure this goes for lots of other people, too.
2. “gray” for our non-Commonwealth readers.
3. good advice seems to be to test several times over several days.
4. “analog”, I suppose – see [2].
5. this is one of the reasons that authentication systems generally use two factors from the three “something you are”, “something you know”, “something you have”.
6. most real-world data, to be honest.
