

This week is Red Hat Summit, which is being held virtually for the first time because of the Covid-19 crisis. The lock-down has not affected the productivity of the Enarx team, however (at least not negatively), as we have a very exciting demo that we will be showing at Summit. This post should be published at 1100 EDT, 1500 BST, 1400 GMT on Tuesday, 2020-04-28, which is the time that the session which Nathaniel McCallum and I recorded will be released to the world. I hope to be able to link to that once it’s released to the world. But what will we be showing?
Well, to set the scene, and to discover a little more about the Enarx project, you might want to read these articles first (also available in Japanese – visit each article of a link):
Enarx, as you’ll discover, is about running workloads in TEEs (Trusted Execution environments), using WebAssembly, in what we call “Keeps”. It’s a mammoth job, particularly as we’re abstracting away the underlying processor architectures (currently two: Intel’s SGX and AMD’s SEV), so that you, the user, don’t need to worry about them: all you need to do is write and compile your application, then request that it be deployed. Enarx, then, has lots of moving parts, and one of the key tasks for us has been to start the work to abstract away the underlying processor architectures so that we can prepare the runtime layers on top. Here’s a general picture of the software layers, and how they sit on top of the hardware platforms:

What we’re announcing – and demoing – today is that we have an initial implementation of code to allow us to abstract away process-based and VM-based types of architecture (with examples for SGX and SEV), so that we can do this:

This seems deceptively simple, but what’s actually going on under the covers is rather more than is exposed in the picture above. The reality is more like this:

This gives more detail: the application that’s running on both architectures (SGX on the left, SEV on the right) is the very same ELF static-PIE binary. To be clear, this is not only the same source code, compiled for different platforms, but exactly the same binary, with the very same hash signature. What’s pretty astounding about this is that in order to make it run on both platforms, the engineering team has had to write two sets of seriously low-level code, including more than a little Assembly language, providing the “plumbing” to allow the binary to run on both.
This is a very big deal, because although we’ve only implemented a handful of syscalls on each platform – enough to make our simple binary run and print out a message – we now have a framework on which we know we can build. And what’s next? Well, we need to expand that framework so that we can then build the WebAssembly layers which will allow WebAssembly applications to run on top:
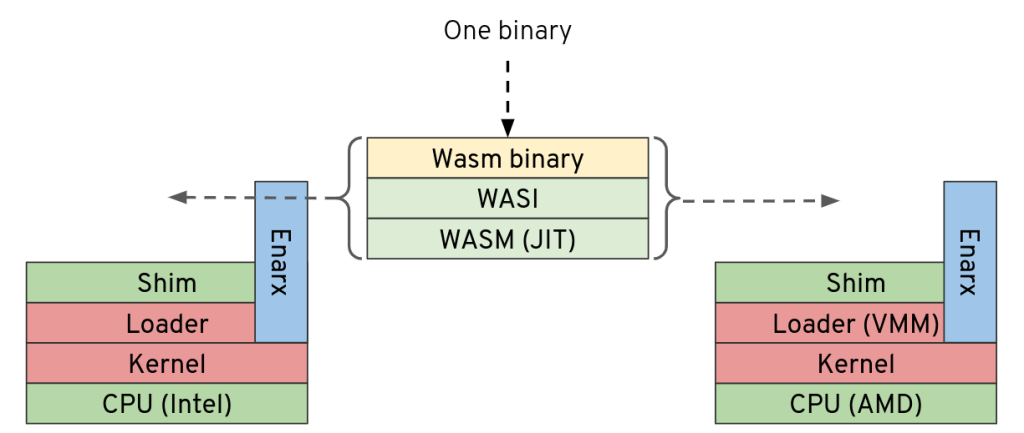
There’s a long way to go, but this milestone shows that we have an initial framework which we can improve, and on which we can build.
What’s next?
What’s exciting about this milestone from our point of view is that we think it puts Enarx at a stage where more people can join and take part. There’s still lots of low-level work to be done, but it’s going to be easier to split up now, and also to start some of the higher level work, too. Enarx is completely open source, and we do all of our design work in the open, along with our daily stand-ups. You’re welcome to browse our documentation, RFCs (mostly in draft at the moment), raise issues, and join our calls. You can find loads more information on the Enarx wiki: we look forward to your involvement in the project.
Last, and not least, I’d like to take a chance to note that we now have testing/CI/CD resources available for the project with both Intel SGX and AMD SEV systems available to us, all courtesy of Packet. This is amazingly generous, and we both thank them and encourage you to visit them and look at their offerings for yourself!

