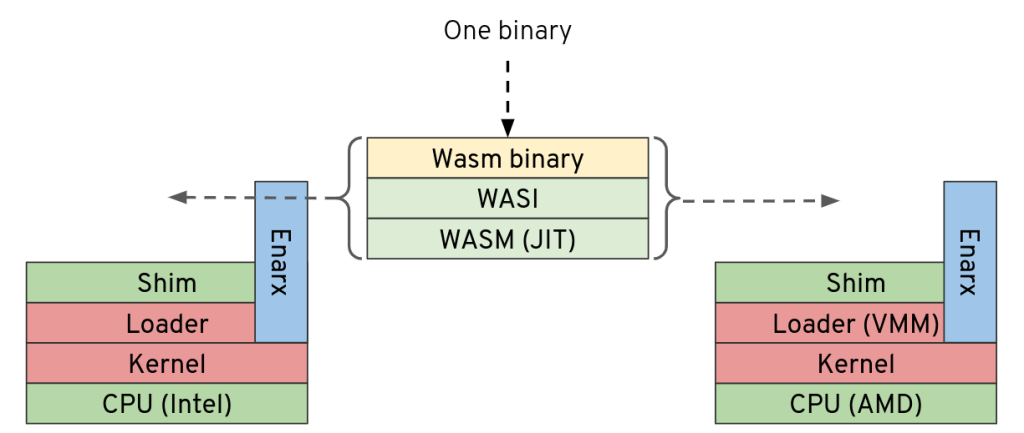
It’s been a long time since I properly learned a new language – computer or human. Maybe 25 years. That language was Java, and although I’ve had to write little bits of C (very, very little) and Javascript in the meantime, the only two languages I’ve written much actual code in have been Perl and Java. As I’ve posted before, I’m co-founder of a project called Enarx (latest details here), which is written almost entirely in Rust. These days I call myself an “architect”, and it’s been quite a long time since I wrote any production code. In the lead up to Christmas last year (2019), I completed the first significant project I’ve written in quite a few years: an implementation of a set of algorithms around a patent application, in Java. It was a good opportunity to get my head back into code, and I was quite pleased with it. I wrote it with half a mind to compile it into WebAssembly as a candidate workload for Enarx, but actually compiling it turned out to be a bit of a struggle, and work got in the way, so completed a basic implementation, checked it into a private github repository and generally forgot about it.
My involvement with the Enarx project so far has been entirely design and architecture work – plus documentation, marketing, evangelism, community work and the rest, but no coding. I have suggested, on occasion – almost entirely in jest – that I commit some code to the project in Perl, and it’s become a bit of a running joke that this would be the extent of any code I submitted, as possibly my involvement with the project, as it would be immediately rejected. And then, about a week and a half ago, I decided to learn Rust. And then to rewrite (including, where necessarily refactoring) that Java project I wrote a few months ago. Here are some of my thoughts on Rust, from the point of a view of a Java developer with a strong Object-Oriented background.
1. Rust feels familiar
Although many of the tutorials and books you’ll find out there are written with C and C++in mind, there’s enough similarity with Java to make the general language feel familiar. The two tutorials I’ve been using the most are The Rust Programming Language online and Programming Rust in dead tree format, and the latter makes frequent references to similarities and differences to and from other languages, including not only C, C++ and Java, but also Python, Javascript and others. Things like control structures and types are similar enough to Java that they’re generally simple to understand, and although there are some major differences, you should be able to get your head round the basics of the language pretty simply. Beware, however: one of the biggest initial problems I’ve been having is that Rust sometimes feels too familiar, so I start trying to do things in the wrong way, have to back out, and try to work out a better way: a way which is more idiomatic to Rust. I have a long way to go on this!
2. References make sense
In Rust, you end up having to use references. Frankly, referencing and de-referencing variables was something that never made much sense to me when I looked at C or C++, but this time, it feels like I get it. If you’re used to passing Java variables by reference and value, and know when you need to take steps to do so differently in specific situations, then you’re ready to start understanding Rust references. The other thing you need to understand is why Rust needs you to use them: it’s because Rust is very, very careful about memory management, and you don’t have a Garbage Collector to clean up after you wherever you go (as in Java). You can’t just pass Strings (for instance) around willy-nilly: Rust is going to insist that you know the lifetime of a variable, and think about when it’s ready to be “dropped”. This means that you need to think hard about scope, and introduces a complex concept: ownership.
3. Ownership will make sense
Honestly, I’m not there yet. I’ve been learning and coding in Rust for under two weeks, and I’m beginning to get my head around ownership. For me (as, I suspect, for many newcomers), this is the big head-shift around moving to Rust from Java or most other languages: ownership. As I mentioned above, you need to understand when a variable is going to be used, and how long it will live. There’s more to it than that, however, and really getting this is something which feels a little foreign to me as a Java developer: you need to understand about the stack and the heap, a distinction which was sufficiently concealed from me by Java, but something which many C and C++ developers will probably understand much more easily. This isn’t the place to explain the concept (I’ve found the diagrams in Programming Rust particularly helpful), but in order to manage the lifetime of variables in memory, Rust is going to need to know what component owns each one. This gets complicated when you’re used to creating objects and instantiating them with variables from all over the place (as in Java), and requires some significant rethinking. Combining this with explicit marking of lifetimes is the biggest conceptual change that I’m having to perform right now.
4. Cargo is helpful
I honestly don’t use the latest and greatest Java tools properly. When I started to learn Java, it wasn’t even in 1.0, and by the time I finished writing production code on a regular basis, there wasn’t yet any need to pick up the very latest tooling, so it may be that Java is better at this than I remember, but the in-built tools for managing the various pieces of a Rust project, including dependencies, libraries, compilation and testing, are a revelation. The cargo binary just does the right thing, and it’s amazing to watch it do its job when it realises that you’ve made a change to your dependencies, for instance. It will perform automatic tests, optimise automatically, produce documentation – so many useful tasks, all within one package. Combine this with git repositories, and managing projects becomes saner and easier.
5. The compiler is amazing
Last, but very far from least, is the compiler. I love the Rust compiler: it really, really tries to help you. The members of the community[1] that makes and maintains clearly go out of their way to provide helpful guidance to correct you when you make mistakes – and I, for one, have been making many of them. Rather than the oracular pronouncements that may be familiar from other languages’ compilers, you’ll get colour-coded text with warnings and errors, and suggestions as to what you might actually be trying to do. You will even be given output such as For more information about this error, try rustc --explain E0308. When you do try this, you get (generally!) helpful explanation and code snippets. Sometimes, particularly when you’re still working your way into the language, it’s not always obvious what you’re doing wrong, but wading through the errors can help you get your head round the concepts in a way which feels very different to messages I’m used to getting from javac, for example.
Conclusion
I don’t expect ever to be writing lots of production Rust, nor ever truly to achieve guru status – in Rust or any other language, to be honest – but I really think that Rust has a lot to be said for it. Throughout my journey so far, I’ve been nodding my head and thinking “that’s a good way to do that”, or “ah, that makes so much more sense than the way I’m used to”. This isn’t an article about why Rust is such a good language – there are loads of those – nor about the best way to learn Rust – there are lots of those, too – but I can say that I’m enjoying it. It’s challenging, but one thing that the tutorials, books and other learning materials are all strong on is explaining the reasons for the choices that Rust makes, and that’s certainly been helpful to me, both in tackling my frustrations, but also in trying to internalise some of the differences between Java and Rust.
If I can get my head truly into Rust, I honestly don’t think I’m likely to write any Java ever again. I’m not sure I’ve got another 25 years of coding in me, but I think that I’m with Rust for the long haul now. I’m a (budding) Rustacean.
1 – Rust, of course, is completely open source, and the community support for it seems amazing.