It’s being a big month for Enarx. Last week, I announced that we’d released Enarx 0.3.0 (Chittorgarh Fort), with some big back-end changes, and some new functionality as well. This week, the news is that we’ve hit a couple of milestones around activity and involvement in the project.
1500 commits
The first milestone is 1500 commits to the core project repository. When you use a git-based system, each time you make a change to a file or set of files (including deleting old ones, creating new one and editing or removing sections), you create a new commit. Each commit has a rather long identifier, and its position in the project is also recorded, along with the name provided by the committer and any comments. Commit 1500 to the enarx was from Nathaniel McCallum, and entitled feat(wasmldr): add Platform API. He committed it on Saturday, 2022-03-19, and its commit number is 8ec77de0104c0f33e7dd735c245f3b4aa91bb4d2.
I should point out that this isn’t the 1500th commit to the Enarx project, but the 1500th commit to the enarx/enarx repository on GitHub. This is the core repository for the Enarx project, but there are quite a few others, some of which also have lots of commits. As an example, the enarx/enarx-shim-sgx repository ,which provides some SGX-specific capabilities within Enarx, had 968 commits at time of writing.
500 Github stars
The second milestone is 500 GitHub stars. Stars are measure of how popular a repository or project is, and you can think of them as the Github of a “like” on social media: people who are interested in it can easily click a button on the repository page to “star” it (they can “unstar” it, too, if they change their mind). We only tend to count stars on the main enarx/enarx repository, as that’s the core one for the Enarx project. The 500th star was given to the project by a GitHub user going by the username shebuel-oss, a self-described “Open Source contributor, Advocate, and Community builder”: we’re really pleased to have attracted their interest!
There’s a handy little website which allows you to track stars to a project called GitHub Star History where you can track the addition (or removal!) of stars, and compare other projects. You can check the status of Enarx whenever you’re reading by following this link, but for the purposes of this article, the important question is how did we get to 500? Here’s a graph:
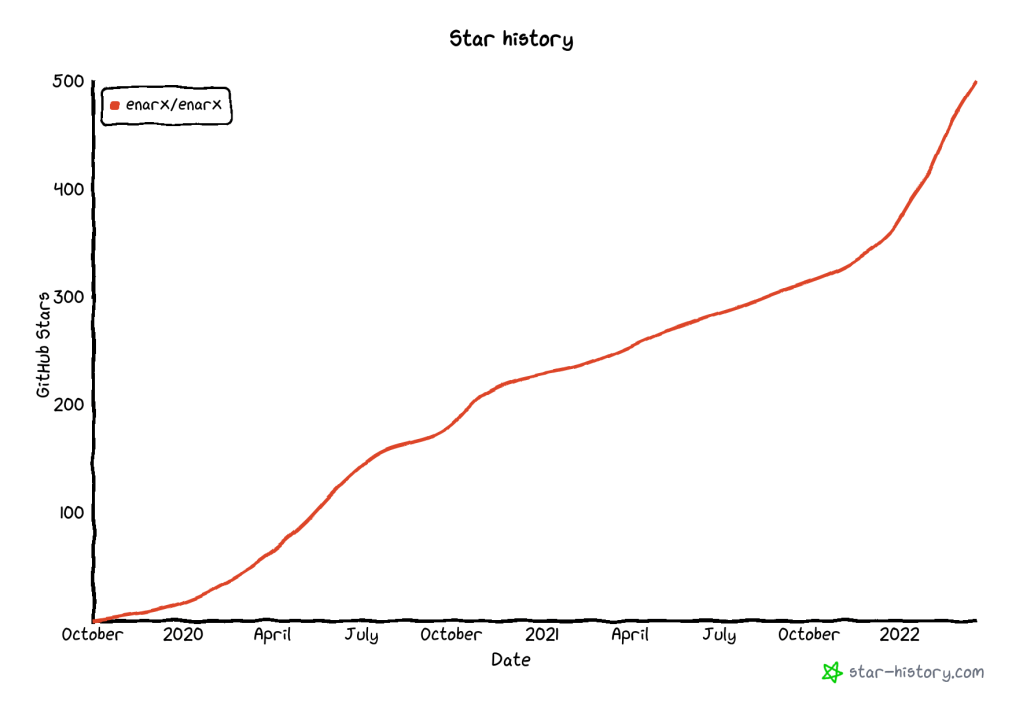
You’ll see a nice steep line towards the end which corresponds to Nick Vidal’s influence as community manager, actively working to encourage more interest and involvement, and contributions to the Enarx project.
Why do these numbers matter?
Objectively, they don’t, if I’m honest: we could equally easily have chosen a nice power of two (like 512) for the number of stars, or the year that Michelangelo started work on the statue David (1501) for the number of commits. Most humans, however like round decimal numbers, and the fact that we hit 1500 and 500 commits and stars respectively within a couple of days of each provides a nice visual symmetry.
Subjectively, there’s the fact that we get to track the growth in interest (and the acceleration in growth) and contribution via these two measurements and their historical figures. The Enarx project is doing very well by these criteria, and that means that we’re beginning to get more visibility of the project. This is good for the project, it’s good for Profian (the company Nathaniel and I founded last year to take Enarx to market) and I believe that it’s good for Confidential Computing and open source more generally.
But don’t take my word for it: come and find out about the project and get involved.