Whether your interests lie in research, design, engineering or operations, there will be opportunities to find rewarding careers in Confidential Computing.
An IDC report published at the end of Q4 2025, revealed that nearly 75% of respondents saw “Lack of skilled personnel” as a hurdle to adopting Confidential Computing. I was recently speaking at a conference on the subject of security – including, of course, Confidential Computing – and was answering questions in the hallway afterwards when someone asked me, “how would you suggest I start a career in Confidential Computing?” The person asking was an engineer and had a good understanding of the basics, having spent some time a year or so ago trying out the technology, but now wanted advice on how to forge a career in the area. As the Executive Director of the Confidential Computing Consortium, this felt like a topic on which I should have an opinion: I thought it might be interesting and useful to provide my thoughts here in an attempt to help fill the perceived gap in the expertise market.
There are, I think, four broad areas – though I initially replied with three – for someone looking to pursue a technical career in Confidential Computing. There’s definitely overlap, and also opportunities for non-technical paths, but I’m going to concentrate on engineering-related, or at least heavily technical roles:
Research
Infrastructure
CC-dedicated
Generalist
Research
In Q2 of 2026, the CCC published a call for research proposals to receive funding from a grant fund. We expected a handful and received over 35 applications and several after the cut-off date. This signals that research in Confidential Computing topics is alive and well within academia. Some of these will be around low-level hardware and firmware, others much higher up the stack in, for instance, attestation and endorsement protocols. There are also opportunities for research outside academia in some of the key companies in this space who are building the infrastructure for Confidential Computing, but also for independent researchers interested in working on specific projects or vulnerabilities. As Confidential Computing matures and more use cases emerge, we can expect research opportunities to continue to grow.
Infrastructure
The industry needs to build out the infrastructure to allow Confidential Computing to become fully commoditised – and then to create offerings that provide ways for providers to differentiate themselves. This area is particularly broad, as it encompasses everything from silicon design to cloud computing services such as key management services and all the way to Attestation Verification Services (AVS). It also includes, as the Research area does not, roles within operations which can expect to look different to existing operations roles as monitoring, debugging and management techniques adapt to Confidential Computing. Many of these jobs will be in silicon vendors, OEMS, hyperscalers and cloud service providers, but there are also likely to be existing enterprises and new start-ups who will be finding a niche in the Confidential Computing services market and need talented and expert engineering resources to succeed.
CC-dedicated
This area maybe overlaps a little with the enterprises and start-ups looking for a niche in the Confidential Computing ecosystem, but, more specifically refers to applications and services that make use of Confidential Computing in new ways, or adapt existing products to make the most of Confidential Computing, enabling new offerings to be provided to the market. There are already many start-ups who have identified market opportunities opened up by Confidential Computing in pretty much any sector you can imagine, leveraging the capabilities of TEEs and the enabling power of attestation to do new things or existing things more securely. Such organisations will need engineers ready to work closely with product and service teams to build applications and frameworks that require deep understanding of Confidential Computing and how it works in a specific engineering context.
Generalist
Where engineers within a CC-dedicated organisation need to work in a specific engineering context, the generalist area is one suited to those who want to help spread Confidential Computing more widely. This sort of role will see people working either as an internal or independent consultant or as a part of a security team looking to help organisations extend their use of Confidential Computing to existing or new applications and services. They may specialise in Confidential Computing technologies and how to apply them, or have them as part of their larger engineering, design or architectural armoury in the same way that experts in the use and application of cryptography might advise an engineering team on how to build security primitives into their component or how on how to apply cryptographic protocols to a larger system. In either case, technologists following this path are likely to encounter a variety of different applications of Confidential Computing and will need to be able to apply the appropriate primitives, tools and techniques to the job in hand.
Conclusion
As Confidential Computing becomes more established as a “must-have” technology and the ecosystem continues to expand, we will continue to build a talent base of expert engineers. Whether your interests lie in research, design, engineering or operations, there will be opportunities to find rewarding careers in Confidential Computing.
Technologies, when combined, sometimes yield fascinating – and commercially exciting – results.
Mike Bursell
Sponsored by Super Protocol
Introduction
One of the things that I enjoy the most is taking two different technologies, accelerating them at speed and seeing what comes out when they hit, rather in the style of a particle physicist with a Large Hadron Collider. Technologies which may not seem to be obvious fits for each other, when combined, sometimes yield fascinating – and commercially exciting – results, and the idea of putting Web3 and Confidential Computing together is certainly one of those occasions. Like most great ideas, once someone explained it to me, it was a “oh, well, of course that’s going to make sense!” moment, and I’m hoping that this article, which attempts to explain the combination of the two technologies, will give you the same reaction. I’ll start with an introduction to the two technologies separately, why they are interesting from a business context, and then look at what happens when you put them together. We’ll finish with more of a description of a particular implementation: that of Super Protocol, using the Polygon blockchain.
Business context
Introduction to the technologies
In this section, we look at blockchain in general and Web3 in particular, followed by a description of the key aspects of Confidential Computing. If you’re already an expert in either of these technologies, feel free to skip these, of course.
Blockchain
Blockchains offer a way for groups of people to agree about the truth of key aspects of the world. They let people say: “the information that is part of that blockchain is locked in, and we – the other people who use it and I – believe that is correct and represents a true version of certain facts.” This is a powerful capability, but how does it arise? The key point about a blockchain is that it is immutable. More specifically, anything that is placed on the blockchain can’t be changed without such a change being obvious to anybody with access to it. And another key point about many blockchains is that they are public – that is, anybody with access to the Internet and the relevant software is able to access them. Such blockchains are sometimes called “permissionless”, in juxtaposition to blockchains to which only authorised entities have access, which are known as “permissioned”. In both cases, the act of putting something on a blockchain is very important – if we want to view blockchains as providing a source of truth about the world – then the ability to put something onto the blockchain is a power that comes with great responsibility. The various consensus mechanisms employed vary between implementations but all of them aim for consensus among the parties that are placing their trust in the blockchain, a consensus that what is being represented is correct and valid. Once such a consensus has been met a cryptographichash is used to seal the latest information and anchor it to previous parts of the blockchain, adding a new block to it.
While this provides enough for some use cases, the addition of smart contracts provides a new dimension of capabilities. I’ve noted before that smart contracts aren’t very well named (they’re arguably neither smart nor contracts!), but what they basically allow is for programs and their results to be put on a blockchain. If I create a smart contract and there’s consensus that it allows deterministic results from known inputs, and it’s put onto the blockchain, then that means that when it’s run, if people can see the inputs – and be assured that the contract was run correctly, a point to which we’ll be returning later in this article – then they will happy to put the results of that smart contract on the blockchain. What we’ve just created is a way to create data that is known to be correct and valid, and which we can be happy to put directly on the blockchain without further checking: the blockchain can basically add results to itself!
Web3
Blockchains and smart contracts, on their own, are little more than a diverting combination of cryptography and computing: it’s the use cases that make things interesting. The first use case that everyone thinks of is crypto-currency, the use of blockchains to create wholly electronic currencies that can be (but don’t have) divorced from centralised government-backed banking systems. (Parenthetically, the fact that the field of use and study of these crypto-currencies has become known to its enthusiasts as “crypto” drives most experts in the much older and more academic field of cryptology wild.)
There are other uses of blockchains and smart contracts, however, and the one which occupies our attention here is Web3. I’m old (I’m not going to give a precise age, but let’s say early-to-mid Gen X, shall we?), so I cut my professional teeth on the technologies that make up what are now known as Web1. Web1 was the world of people running their own websites with fairly simple static pages and CGI interactions with online databases. Web2 came next and revolves around centralised platforms – often cloud-based – and user-generated data, typically processed and manipulated by large organisations. While data and information may be generated by users, it’s typically sucked into the platforms owned by these large organisations (banks, social media companies, governments, etc.), and passes almost entirely out of user control. Web3 is the next iteration, and the big change is that it’s a move to decentralised services, transparency and user control of data. Web3 is about open protocols – data and information isn’t owned by those processing it: Web3 provides a language of communication and says “let’s start here”. And Web3 would be impossible without the use of blockchains and smart contracts.
Confidential Computing
Confidential Computing is a set of technologies that arose in the mid 2010s, originally to address a number of the problems that people started to realise were associated with cloud computing and Web2. As organisations moved their applications to the cloud, it followed that the data they were processing also moved there, and this caused issues. It’s probably safe to say that the first concerns that surfaced were around the organisations’ own data. Keeping financial data, intellectual property, cryptographic keys and the like safe from prying eyes on servers operated in clouds owned and managed by completely different companies, sometimes in completely different jurisdictions, started to become a worry. But that worry was compounded by the rising tide of regulation being enacted to protect the data not of the organisations, but of the customers who they (supposedly) served. This, and the growing reputational damage associated with the loss of private data, required technologies that would allow the safeguarding of sensitive data and applications from the cloud service providers and, in some cases, from the organisations who “owned” – or at least processed – that data themselves.
Confidential Computing requires two main elements. The first is a hardware-based Trusted Execution Environment (TEE): a set of capabilities on a chip (typically a CPU or GPU at this point) that can isolate applications and their data from the rest of the system running them, including administrators, the operating system and even the lowest levels of the computer, the kernel itself. Even someone with physical access to the machine cannot overcome the protection that a TEE provides, except in truly exceptional circumstances. The second element is remote attestation. It’s all very well setting up a TEE on a system in, say, a public cloud, but how can you know that it’s actually in place or even that the application you wanted to load into it is the one that’s actually running? Remote attestation addresses this problem in a multi-step process. There are a number of ways to manage this, but the basic idea is that the application in the TEE asks the CPU (which understands how this works) to create a measurement of some or all of the memory in the TEE. The CPU does this, and signs this with a cryptographic key, creating an attestation measurement. This measurement is then passed to a different system (hence “remote”), which checks it to see if it conforms to the expectations of the party (or parties) running the application and, if it does, provides a verification confirms that all is well. This basically allows a certificate to be created that attests to the correctness of the CPU, the validity of the TEE’s configuration and the state of any applications or data within the TEE.
With these elements – TEEs and remote attestation – in place, organisations can use Confidential Computing to prove to themselves, their regulators and their customers that no unauthorised peeking or tampering is possible with those sensitive applications and data that need to be protected.
Combining blockchain & CC
One thing – possibly the key thing – about Web3 is that it’s decentralised. That means that anyone can offer to provide services and, most importantly, computing services, to anybody else. This means that you don’t need to go to one of the big (and expensive) cloud service providers to run your application – you can run a DApp (Decentralised Application) – or a standard application such as a simple container image – on the hardware of anyone willing to host it. The question, of course, is whether you can trust them with your application and your data; and the answer, of course in many, if not most, use cases, is “no”. Cloud service providers may not be entirely worthy of organisations’ trust – hence the need for Confidential Computing – but at least they are publicly identifiable, have reputations and are both shameable and suable. It’s very difficult to say the same about in a Web3 world about a provider of computing resources who may be anonymous or pseudonymous and with whom you have never had any interactions before – nor are likely to have any in the future. And while there is sometimes scepticism about whether independent actors can create complex computational infrastructure, we only need look at the example of Bitcoin and other cryptocurrency miners, who have built computational resources which rival those of even the largest cloud providers.
Luckily for Web3, it turns out that Confidential Computing, while designed primarily for Web2, has just the properties needed to allow us to build systems that do allow us to do Web3 computing with confidence (I’ll walk through some of the key elements of one such implementation – by Super Protocol – below). TEEs allow DApps to be isolated from the underlying hardware and system software and remote attestation can provide assurances to clients that everything has been set up correctly (and a number of other properties besides).
Open source
There is one important characteristic that Web3 and Confidential Computing share that is required to ensure the security and transparency that is a key to a system that combines them: open source software. Where software is proprietary and closed from scrutiny (this is the closed from which open source is differentiated), the development of trust in the various components and how they interact is impossible. Where proprietary software might allow trust in a closed system of actors and clients who already have trust with each other – or external mechanisms to establish it – the same is not true in a system such as Web3 whose very decentralised nature doesn’t allow for such centralised authorities.
Open source software is not automatically or by its very nature more secure than proprietary software – it is written by humans, after all (for now!), and – but its openness and availability to scrutiny means that experts can examine it, check it and, where necessary, fix it. This allows the open source community and those that interact with it to establish that it is worthy of trust in particular contexts and use cases (see Chapter 9: Open Source and Trust in my book for more details of how this can work). Confidential Computing – using TEEs and remote attestation – can provide cryptographic assurances not only the elements of a Web3 system are valid and have appropriate security properties, but also that the components of the TEE itself do as well.
Some readers may have noted the apparent circularity in this set-up – there are actually two trust relationships that are required for Confidential Computing to work: in the chip manufacturer and in the attestation verification service. The first of these is unavoidable with current systems, while the other can be managed in part by performing the attestation oneself. It turns out that allowing the creation of trust relationships between mutually un-trusting parties is extremely complex, but one way that this can be done is what we will now address.
Super Protocol’s approach
Super Protocol have created a system which uses Confidential Computing to allow execution of complex applications to be made within a smart contract on the blockchain and for all the parties in the transaction to have appropriate trust in the performance and result of that execution without having to know or trust each other. The key layers are:
Client Infrastructure, allowing a client to interact with the blockchain, initiate an instance and interact with it
Blockchain, including smart contracts
Various providers (TEE, Data, Solution, Storage).
Central to Super Protocol’s approach are two aspects of the system: that it is open source, and that remote attestation is required to allow the client to have sufficient assurance of the system’s security. Smart contracts – themselves open source – allow the resources made available by the various actors and combined into an offer that is placed on the blockchain and is available to anyone with access to the blockchain – to execute it, given sufficient resources from all involved. What makes this approach a Web3 approach, and differentiates it from a more Web2 system, is that none of these actors needs to be connected contractually.
Benefits of This Approach
How does this approach help? Well, you don’t need to store or process data (which may be sensitive or just very large) locally: TEEs can handle it, providing confidentiality and integrity assurances that would otherwise be impossible. And communications between the various applications are also encrypted transparently, reducing or removing risks of data leakage and exposure, without requiring complex key management by users, but keeping the flexibility and exposure offered by decentralisation and Confidential Computing.
But the step change that this opens up is the network effect enabled by the possibility of building huge numbers of interconnected Web3 agents and applications, operating with the benefits of integrity and confidentiality offered by Confidential Computing, and backed up by remote attestation. One of the recurring criticisms of Web2 ecosystems is their fragility and lack of flexibility (not to mention the problems of securing them in the first place): here we have an opportunity to create complex, flexible and robust ecosystems where decentralised agents and applications can collaborate, with privacy controls designed in and clearly defined security assurances and policies.
Technical details
In this section, I dig a little further into some of the technical details of Super Protocol’s system. It is, of course, not the only approach to combining Confidential Computing and Web3, but it is available right now, seems carefully architected and designed with security foremost in mind and provides a good example of the technologies and the complexities involved.
You can think of Super Protocol’s service as being in two main parts: on-chain and off-chain. The marketplace, with smart contract offers, sits on an Ethereum blockchain, and the client interacts with that, never needing to know the details of how and where their application instance is running. The actual running applications are off-chain, supported by other infrastructure to allow initial configuration and then communication services between clients and running applications. The “bridge” between the two parts, which moves from an offer to an actual running instance of the application, is a component called a Trusted Loader, which sets up the various parts of the application and sets it running. The data it is managing contains sensitive information such as cryptographic keys which need to be protected as they provide security for all the other parts of the system and the Trusted Loader also manages the important actions of hash verification (ensuring that what is being loaded what was originally offered) and order integrity (ensuring that no changes can be made whilst the loading is taking place and execution starting).
Trusted Loader – configuration and deployment with Data and Application information into TEE instance
But what is actually running? The answer is that the unit of execution for an application in this service is a Kubernetes Pod, so each application is basically a container image which is run within a Pod, which itself executes within a TEE, isolating it from any unauthorised access. This Pod itself is – of course! – measured, creating an attestation measurement that can now be verified by clients of the application. We should also remember that the application itself – the container image – needs protection as well. This is part of the job of the Trusted Loader, as the container image is stored encrypted, and the Trusted Loader has appropriate keys to decrypt this and other resources required to allow execution. This is not the only thing that the Trusted Loader does: it also gathers and sets up resources from the smart contract for networking and storage, putting everything together, setting it running and connecting the client to the running instance.
There isn’t space in this article to go into deeper detail of how the system works, but by combining the capabilities offered by Confidential Computing and a system of cryptographic keys and certificates, the overall system enforces a variety of properties that are vital for sensitive, distributed and decentralised Web3 applications.
Decentralised storage: secrets are kept in multiple places instead of one, making them harder to access, steal or leak.
Developer independence: creators of applications can’t access these secrets, continuing the lack of need for trust relationships between the various actors. In other words, each instance of an application is isolated from its creator, maintaining data confidentiality.
Unique secrets: Each application gets its own unique secrets that nobody else can use or see and which are not shared between instances.
Thanks
Thanks to Super Protocol for sponsoring this article. Although they made suggestions and provided assistance around the technical details, this article represents my views, the text is mine and final editorial control (and with it the blame for any mistakes!) rests with the author.
Towards the end of April this year (2023), I joined the Confidential Computing Consortium as the Executive Director, and I thought it might be interesting to reflect on what that means. I’ve been involved with the CCC since its foundation in October 2019: in fact, I was one of those who helped shape it and move it to foundation from its inception a few months earlier. I have, at various times, acted as the Red Hat (Premier Member) representative on the Governing Board, project representative for Enarx, Treasurer, member as part of Profian, and General Member representative before a brief period of a couple of months as we closed down Profian where I wasn’t involved. I’ve spoken for the CCC at conferences, staffed booths, written blog posts, contributed to white papers, helped commission a market report, recruit members and pretty much everything else that is involved in a Linux Foundation project. It’s been a fairly large part of my professional life for approaching four years.
So I was very happy to be invited to become invited to apply to be Executive Director, a position that had been mooted while I was still involved in the consortium, but which I’d had no expectation of being approached about. But what does an Executive Director do? I don’t see any reason not to share a cut-down version of the role description as per the contract (redacted just for brevity, and not any reasons of confidentiality):
Attending events, speaking, providing booth presence, etc.
Blogging as appropriate, participating in podcasts, etc. to raise awareness about the CCC and its mission.
Engage premier and general members to encourage involvement and solicit feedback, helping the governing board set goals and milestones if appropriate, and generally taking the pulse of the organization from the members’ perspective.
Recruit new membership from relevant organizations.
Recruit new projects to the CCC.
Attend Governing Board meetings and report on work to date and plans for the next period. Report out via simple slides for the governing board presentation.
This is a short but very broad brief and it raises the question: does an Executive Director direct things (are they foremost a manager?) or execute things (are they foremost a task performer?)?
The answer, of course, will vary from organisation to organisation and I know that is true even between the Executive Directors for different Linux Foundation projects, but for me, it’s a (sometimes uneasy) “both”. Member organisations are both blessed and plagued by the fact that, to start with, nothing gets done unless members’ employees do it. They need to arrange meetings, organise conference attendance, manage webinars, write white papers and all the rest. They may get some implementation help for some of these (the Linux Foundation, for example, has a number of functions which can provide help for particular specialist functions like marketing, research or project management), but most of it is run by the members and their employees. And then they get to the stage where they decide that they need some help at a senior level.
What does that person do? Well, here are some words that I think of when I consider my role:
support
chivy
encourage
recruit
explain
advertise
represent
engage
report
You’ll note that some of these are words that are about working with people or members (e.g. support, engage, encourage), whereas others are more about doing things (e.g. advertise, explain, represent). The former feel more like the “directing” part of the role and the latter feel more like the “executing” part of the role. Obviously, they’re not mutually incompatible, and some of the words can lean in both directions, which makes it even more clear to me that it’s hybrid role that I’m fulfilling.
Given my hybrid background (as a techie with business experience), this feels appropriate, and I need to keep ensuring that I balance the time I spend on different activities carefully: I can neither spend all my time on making technical comments on a draft report on GRC (governance, risk management and compliance) nor on considering recruitment options for new members in the Asia Pacific region. But at the same time, it feels sensible that, as someone tasked with having an overview of the organisation, I keep at least some involvement (or knowledge of) all the major moving parts.
It doesn’t change the fact, however, that things only really get done when members get involved, too. This is one of those areas where it’s entirely clear to me that I can only execute tasks to a certain level: this has to be a collaborative role, which frankly suits me and my management style very well. The extent to which I keep an eye on most things, and the balance of work between me, members and other functions of the organisation are likely to change as we continue to grow, but for now, I’m very much enjoying the work I’m doing (and the interactions with the people I’m doing it with) and juggling the balance of executing versus direction.
the original idea, as conceived, has a great deal of merit;
few people really understand what it means;
it’s become an industry bandwagon that is sorely abused by some security companies;
it would be better called “explicit trust”.
The reason for this last is that it’s impossible to have zero trust: any entity or component has to have some level of trust in the other entities/components with which it interacts. More specifically, it has to maintain trust relationships – and what they look like, how they’re established, evaluated, maintained and destroyed is the core point of discussion of my book Trust in Computer Systems and the Cloud. If you’re interested in a more complete and reasoned criticism of zero trust, you’ll find that in Chapter 5: The Importance of Systems.
But, as noted above, I’m actually in favour of the original idea of zero trust, and that’s why I wanted to write this article about how zero trust and Confidential Computing, when combined, can actually provide some real value and improvements over standard distributed architectures (particularly in the Cloud).
An important starting point, however, is to note that I’ll be using this definition of Confidential Computing:
Confidential Computing is the protection of data in use by performing computation in a hardware-based, attested Trusted Execution Environment.
Confidential Computing, as thus described, can provide two properties which are excellent starting points for components wishing to exercise zero/explicit trust, which we’ll examine individually:
isolation from the host machine/system, particularly in terms of confidentiality of data;
cryptographically verifiable identity.
Isolation
One of the main trust relationships that any executing component must establish and maintain is with the system that is providing the execution capabilities – the machine on which it is running (or virtual machine – but that presents similar issues). When you say that your component has “zero trust”, but has to trust the host machine on which it is running to maintain the confidentiality of the code and/or data associated with the component, then you have to accept the fact that you do actually have an enormous trust relationship: with the machine and whomever administers/controls it (and that includes anyone who may have compromised it). This can hardly form the basis for a “zero trust” architecture – but what can be done about it?
Where Confidential Computing helps is by allowing isolation from the machine which is doing the execution. The component still needs to trust the CPU/firmware that’s providing the execution context – something needs to run the code, after all! – but we can shrink that number of trust relationships required significantly, and provide cryptographic assurances to base this relationship on (see Attestation, below).
Knowing that a component is isolated from another component allows that component to have assurances about how it will operate and also allows other components to build a trust relationship with that component with the assurance that it is acting with its own agency, rather than under that of a malicious actor.
Attestation
Attestation is the mechanism by which an entity can receive assurances that a Confidential Computing component has been correctly set up and can provide the expected properties of data confidentiality and integrity and code integrity (and in some cases, confidentiality). These assurances are bound to a particular Confidential Computing component (and the Trusted Execution Environment in which it executes) cryptographically, which allows for another property to be provided as well: a unique identity. If the attesting service bind this identity cryptographically to the Confidential Computing component by means of, for instance, a standard X.509 certificate, then this can provide one of the bases for trust relationships both to and from the component.
Establishing a “zero trust” relationship
These properties allow zero (or “explicit”) trust relationships to be established with components that are operating within a Confidential Computing environment, and to do so in ways which have previously been impossible. Using classical computing approaches, any component is at the mercy of the environment within which it is executing, meaning that any trust relationship that is established to it is equally with the environment – that is, the system that is providing its execution environment. This is far from a zero trust relationship, and is also very unlikely to be explicit!
In a Confidential Computing environment, components can have a small number of trust relationships which are explicitly noted (typically these include the attestation service, the CPU/firmware provider and the provider of the executing code), allowing for a much better-defined trust architecture. It may not be exactly “zero trust”, but it is, at least, heading towards “minimal trust”.
A good selection of business-led and technical sessions
It should be around 70F/21C in San Francisco around the 29th June, which is a pretty good reason to pop over to attend the Confidential Computing Summit which is happening on that day. One of the signs that a technology is getting some real attention in the industry is when conferences start popping up, and Confidential Computing is now at the stage where it has two: OC3 (mainly virtual, Europe-based) and CCS.
I have to admit to having skin in this game – as Executive Director of the Confidential Computing Consortium, I’ll be presenting a brief keynote – but given the number of excellent speakers who’ll be there, it’s very much worth considering if you have an interest in Confidential Computing (and you should). I’d planned to paste the agenda into this article, but it’s just too large. Here is a list of just some of the sessions and panels, instead.
State of the Confidential Computing Market – Raluca Ada Popa, Assoc. Prof CS, UC Berkeley and co-founder Opaque Systems
Confidential Computing and Zero Trust – Vikas Bhatia, Head of Product, Microsoft Azure Confidential Computing
Overcoming Barriers to Confidential Computing as a Universal Platform – John Manferdelli, Office of the CTO, VMware
Confidential Computing as a Cornerstone for Cybersecurity Strategies and Compliance – Xochitl Monteon, Chief Privacy Officer and VP Cybersecurity Risk & Governance, Intel
Citadel: Side-Channel-Resistant Enclaves on an Open-Source, Speculative, Out-of-Order Processor – Srini Devadas, Webster Professor of EECS, MIT
Collaborative Confidential Computing: FHE vs sMPC vs Confidential Computing. Security Models and Real World Use Cases – Bruno Grieder, CTO & Co-Founder, Cosmian
Application of confidential computing to Anti Money Laundering in Canada – Vishal Gossain, Practice Leader, Risk Analytics and Strategy, Ernst and Young
As you can tell, there’s a great selection of business-led and technical sessions, so whether you want to delve into the technology or understand the impact of Confidential Computing on business, please come along: I look forward to seeing you there.
I’m very pleased to announce that I’ve just started a new role as part-time Executive Director for the Confidential Computing Consortium, which is a project of the The Linux Foundation. I have been involved from the very earliest days of the consortium, which was founded in 2019, and I’m delighted to be joining as an officer of the project as we move into the next phase of our growth. I look forward to working with existing and future members and helping to expand industry adoption of Confidential Computing.
For those of you who’ve been following what I’ve been up to over the years, this may not be a huge surprise, at least in terms of my involvement, which started right at the beginning of the CCC. In fact, Enarx, the open source project of which I was co-founder, was the very first project to be accepted into the CCC, and Red Hat, where I was Chief Security Architect (in the Office of the CTO) at the time, was one of the founding members. Since then, I’ve served on the Governing Board (twice, once as Red Hat’s representative as a Premier member, and once as an elected representative of the General members) acted as Treasurer, been Co-chair of the Attestation SIG and been extremely active in the Technical Advisory Council. I was instrumental in initiating the creation of the first analyst report into Confidential Computing and helped in the creation of the two technical and one general white paper published by the CCC. I’ve enjoyed working with the brilliant industry leaders who more than ably lead the CCC, many of whom I now count not only as valued colleagues but also as friends.
The position – Executive Director – however, is news. For a while, the CCC has been looking to extend its activities beyond what the current officers of the consortium can manage, given that they have full-time jobs outside the CCC. The consortium has grown to over 40 members now – 8 Premier, 35 General and 8 Associate – and with that comes both the opportunity to engage in a whole new set of activities, but also a responsibility to listen to the various voices of the membership and to ensure that the consortium’s activities are aligned with the expectations and ambitions of the members. Beyond that, as Confidential Computing becomes more pervasive, it’s time to ensure that (as far as possible), there’s a consistent, crisp and compelling set of messages going out to potential adopters of the technology, as well as academics and regulators.
I plan to be working on the issues above. I’ve only just started and there’s a lot to be doing – and the role is only part-time! – but I look forward to furthering the aims of the CCC:
The Confidential Computing Consortium is a community focused on projects securing data in use and accelerating the adoption of confidential computing through open collaboration.
The core mission of the CCC
Wish me luck, or, even better, get in touch and get involved yourself.
There really is no excuse for not protecting your (and your customers’!) data in use.
I came across this article recently: 81% of companies had a cloud security incident in the last year. I think it’s probably factually incorrect, and that the title should be “81% of companies are aware that they had a cloud security incident last year”. Honestly, it could well be much higher than that. When I’ve worked on IT security audits, I sometimes see statements like “[Company X] experienced no data or privacy breaches over the past 12 months”, and I always send it back, insisting on a change of wording to reflect the fact that all that is known is that the organisation is not aware of any data or privacy breaches over the past 12 months.
The other statistic that really struck me in the article, however, is that the top reported type of incident was “Security incidents during runtime”, with 34% of respondents reporting it. That’s over a third of incidents!
And near the top of concerns was “Privacy/data access issues, such as those from GDPR”, at 31%.
The problem about both of these types of issues is that there’s almost nothing you can do to protect yourself from them in the cloud. Cloud computing (and virtualisation in general) is pretty good at protecting you from other workloads (type 1 isolation) and protecting the host from your workloads (type 2 isolation), but offers nothing to protect your workload from the host (type 3 isolation). If you’re interested in a short introduction to why, please have a look at my article Isolationism – not a 4 letter word (in the cloud).
The good news is that there are solutions out there that do allow you to run sensitive applications (and applications with sensitive data) in the cloud: that’s what Confidential Computing is all about. Confidential Computing protects your data not just at rest (when it’s in storage) and in transit (on the network), but actually at runtime: “data in use”. And it seems that industry is beginning to realise that it’s time to be sitting up and paying attention: the problem is that not enough people know about Confidential Computing.
So – now’s the time to become the expert on Confidential Computing for your organisation, and show your manager, your C-levels and your board how to avoid becoming part of the 81% (or the larger, unknowing percentage). The industry body is the Confidential Computing Consortium, and they have lots of information, but if you want to dive straight in, I encourage you to visit Profian and download one or more of our white papers (there’s one about runtime isolation there, as well). There really is no excuse for not protecting your (and your customers’!) data in use.
Without attestation, you’re not really doing Confidential Computing.
This post – or the title of this post – has been sitting in my “draft” pile for about two years. I don’t know how this happened, because I’ve been writing about Confidential Computing for three years or so years by now, and attestation is arguably the most important part of the entire subject.
I know I’ve mentioned attestation in passing multiple times, but this article is devoted entirely to it. If you’re interested in Confidential Computing, then you must be interested in attestation, because, without it, you’re not doing Confidential Computing right. Specifically, without attestation, any assurances you may think you have about Confidential Computing are worthless.
Let’s remind ourselves what Confidential Computing is: it’s the protection of applications and data in use by a hardware-based TEE (Trusted Execution Environment). The key benefit that this brings you is isolation from the host running your workload: you can run applications in the public cloud, on premises or in the Edge, and have cryptographic assurances that no one with access to the host system – hypervisor access, kernel access, admin access, even standard hardware access[1] – can tamper with your application. This, specifically, is Type 3 – workload from host – isolation (see my article Isolationism – not a 4 letter word (in the cloud) for more details), and is provided by TEEs such as AMD’s SEV and Intel’s SGX – though not, crucially, by AWS Nitro, which does not provide Confidential Computing capabilities as defined by the Confidential Computing Consortium.
Without attestation, you’re not really doing Confidential Computing. Let’s consider a scenario where you want to deploy an application using Confidential Computing on a public cloud. You ask your CSP (Cloud Service Provider) to deploy it. The CSP does so. Great – your application is now protected: or is it? Well, you have no way to tell, because your CSP could just have taken your application, deployed it in the normal way, and told you that it had deployed it using a TEE. What you need is to take advantage of a capability that TEE chips provide called an attestation measurement to check that a TEE instance was actually launched and that your application was deployed into it. You (or your application) asks the TEE-enabled chip to perform a cryptographically signed measurement of the TEE set-up (which is basically a set of encrypted memory pages). It does so, and that measurement can then be checked to ensure that it has been correctly set up: there’s a way to judge whether you’re actually doing Confidential Computing.
So, who does that checking? Doing a proper cryptographic check of an attestation measurement – the attestation itself – is surprisingly[2] tricky, and, unless you’re an expert in TEEs and Confidential Computing (and one of the points of Confidential Computing is to make is easy for anyone to use these capabilities), then you probably don’t want to be doing it.
Who can perform the validation? Well, one option might be for the validation to be done on the host machine that’s running the TEE. But wait a moment – that makes no sense! You’re trying to isolate yourself from that machine and anyone who has access to it: that’s the whole point of Confidential Computing. You need a remote attestation service – a service running on a different machine which can be trusted to validate the attestation and either halt execution if it fails, or let you know so that you can halt execution.
So who can run that remote attestation service? The obvious – obvious but very, very wrong – answer is the CSP who’s running your workload. Obvious because, well, they presumably run Confidential Computing workloads for lots of people, but wrong because your CSP is part of your threat model. What does this mean? Well, we talked before about “trying to isolate yourself from that machine and anyone who has access to it”, the anyone who has access to it is exactly your CSP. If the reason to be using Confidential Computing is to be able to put workloads in the public cloud even when you can’t fully trust your CSP (for regulatory reasons, for auditing reasons, or just because you need higher levels of assurance than existing cloud computing), then you can’t trust your CSP to provide the remote attestation service. To be entirely clear: if you allow your CSP to do your attestation, you lose the benefits of Confidential Computing.
Attestation – remote attestation – is vital, but if we can’t trust the host or the CSP to do it, what are your options? Well, either you need to do the attestation yourself (which I already noted is surprisingly difficult), or you’re going to need to find a third party to do that. I’ll be discussing the options for this in a future article – keep an eye out.
1 – the TEEs used for Confidential Computing don’t aim to protect against long-term access to the CPU by a skilled malicious actor – but this isn’t a use case that’s relevant to most users.
2 – actually, not that surprising if you’ve done much work with cryptography, cryptographic libraries, system-level programming or interacted with any silicon vendor documentation.
It’s being a big month for Enarx. Last week, I announced that we’d released Enarx 0.3.0 (Chittorgarh Fort), with some big back-end changes, and some new functionality as well. This week, the news is that we’ve hit a couple of milestones around activity and involvement in the project.
1500 commits
The first milestone is 1500 commits to the core project repository. When you use a git-based system, each time you make a change to a file or set of files (including deleting old ones, creating new one and editing or removing sections), you create a new commit. Each commit has a rather long identifier, and its position in the project is also recorded, along with the name provided by the committer and any comments. Commit 1500 to the enarx was from Nathaniel McCallum, and entitled feat(wasmldr): add Platform API. He committed it on Saturday, 2022-03-19, and its commit number is 8ec77de0104c0f33e7dd735c245f3b4aa91bb4d2.
I should point out that this isn’t the 1500th commit to the Enarx project, but the 1500th commit to the enarx/enarx repository on GitHub. This is the core repository for the Enarx project, but there are quite a few others, some of which also have lots of commits. As an example, the enarx/enarx-shim-sgx repository ,which provides some SGX-specific capabilities within Enarx, had 968 commits at time of writing.
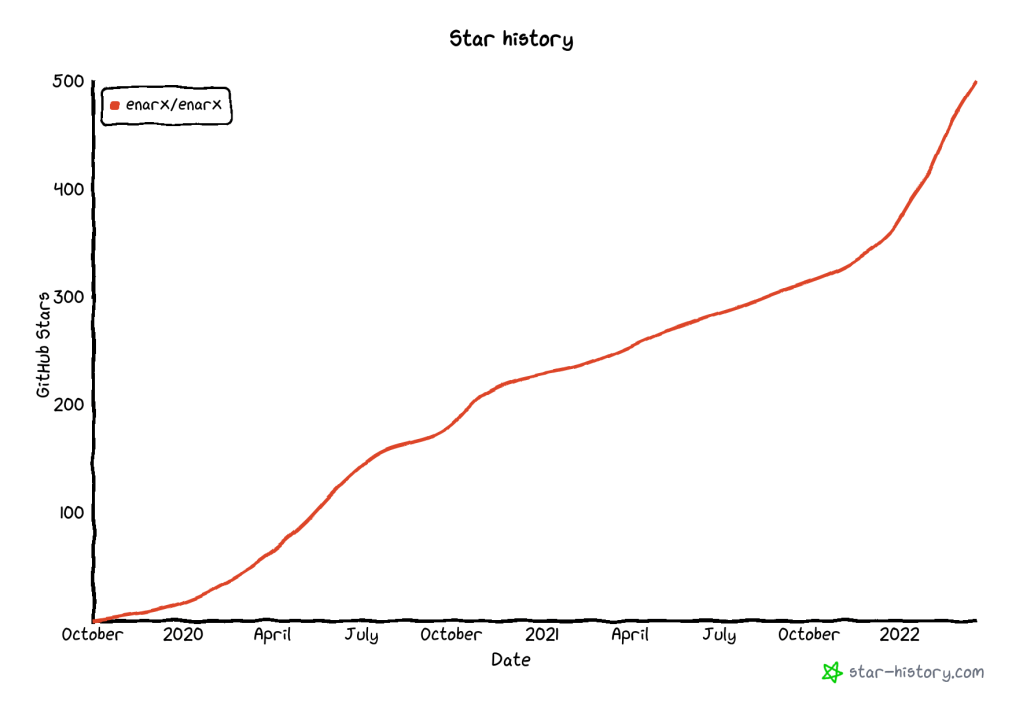
500 Github stars
The second milestone is 500 GitHub stars. Stars are measure of how popular a repository or project is, and you can think of them as the Github of a “like” on social media: people who are interested in it can easily click a button on the repository page to “star” it (they can “unstar” it, too, if they change their mind). We only tend to count stars on the main enarx/enarx repository, as that’s the core one for the Enarx project. The 500th star was given to the project by a GitHub user going by the username shebuel-oss, a self-described “Open Source contributor, Advocate, and Community builder”: we’re really pleased to have attracted their interest!
There’s a handy little website which allows you to track stars to a project called GitHub Star History where you can track the addition (or removal!) of stars, and compare other projects. You can check the status of Enarx whenever you’re reading by following this link, but for the purposes of this article, the important question is how did we get to 500? Here’s a graph:
Enarx GitHub star history to 500 stars
You’ll see a nice steep line towards the end which corresponds to Nick Vidal’s influence as community manager, actively working to encourage more interest and involvement, and contributions to the Enarx project.
Why do these numbers matter?
Objectively, they don’t, if I’m honest: we could equally easily have chosen a nice power of two (like 512) for the number of stars, or the year that Michelangelo started work on the statue David (1501) for the number of commits. Most humans, however like round decimal numbers, and the fact that we hit 1500 and 500 commits and stars respectively within a couple of days of each provides a nice visual symmetry.
Subjectively, there’s the fact that we get to track the growth in interest (and the acceleration in growth) and contribution via these two measurements and their historical figures. The Enarx project is doing very well by these criteria, and that means that we’re beginning to get more visibility of the project. This is good for the project, it’s good for Profian (the company Nathaniel and I founded last year to take Enarx to market) and I believe that it’s good for Confidential Computing and open source more generally.
But don’t take my word for it: come and find out about the project and get involved.
I’ll probably have a glass or two of something tonight.
It’s official: my book is now published and available in the US! What’s more, my author copies have arrived, so I’ve actually got physical copies that I can hold in my hand.
You can buy the book at Wiley’s site here, and pre-order with Amazon (the US site lists is as “currently unavailable”, and the UK site lists is as available from 22nd Feb, 2022. ,though hopefully it’ll be a little earlier than that). Other bookstores are also stocking it.
I’m over the moon: it’s been a long slog, and I’d like to acknowledge not only those I mentioned in last week’s post (Who gets acknowledged?), but everybody else. Particularly, at this point, everyone at Wiley, calling out specifically Jim Minatel, my commissioning editor. I’m currently basking in the glow of something completed before getting back to my actual job, as CEO of Profian. I’ll probably have a glass or two of something tonight. In the meantime, here’s a quote from Bruce Schneier to get you thinking about reading the book.
Trust is a complex and important concept in network security. Bursell neatly unpacks it in this detailed and readable book.
Bruce Schneier, author of Liars and Outliers: Enabling the Trust that Society Needs to Thrive
At least you know what to buy your techy friends for Christmas!