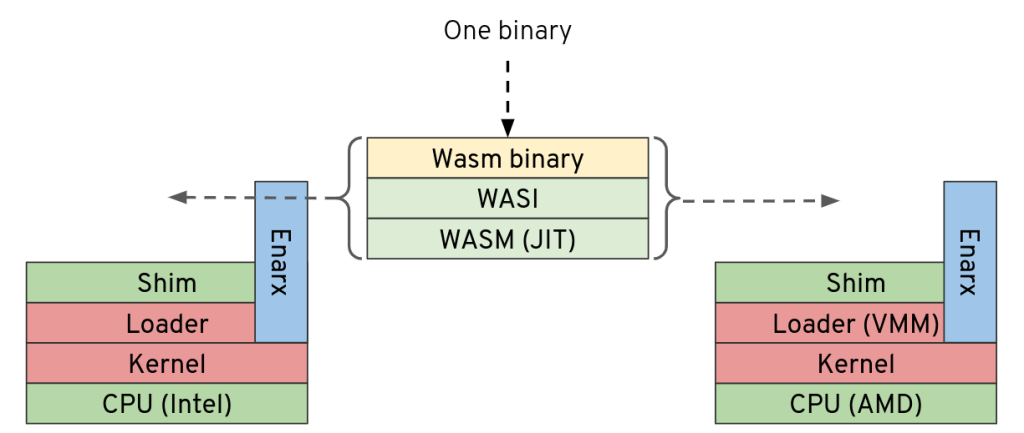
I’ve written lots about the Enarx project, a completely open source project around deploying workloads to Trusted Execution Environments, and you can find a few of the articles here:
I have some very exciting news to announce.
A team effort
Yesterday was a huge day for the Enarx project, in that we now have a fully working end-to-end proof of concept, with no smoke and mirrors (we don’t believe in those). The engineers on the team have been working really hard on getting all of the low-level pieces in place, with support from other members on CI/CD, infrastructure, documentation, community outreach and beyond. I won’t mention everyone, as I don’t want to miss anyone out, and I also don’t have their permission, but it’s been fantastic working with everyone. We’ve been edging closer and closer to having all the main pieces ready to go, and just before Christmas/New Year we got attested AMD SEV Keeps working, with the ability to access information from that attestation within the Keep. This allowed us to move to the final step, which is creating an end-to-end client-server architecture. It is this that we got running yesterday.
I happened to be the lucky person to be able to complete this part of the puzzle, building on work by the rest of the team. I don’t have the low-level expertise that many of the team have, but my background is in client-server and peer-to-peer distributed systems, and after I started learning Rust around March 2020, I decided to see if I could do something useful for the project code base: this is my contribution to the engineering. To give you an idea of what we’ve implemented, let’s look at a simple architectural diagram of an Enarx deployment.
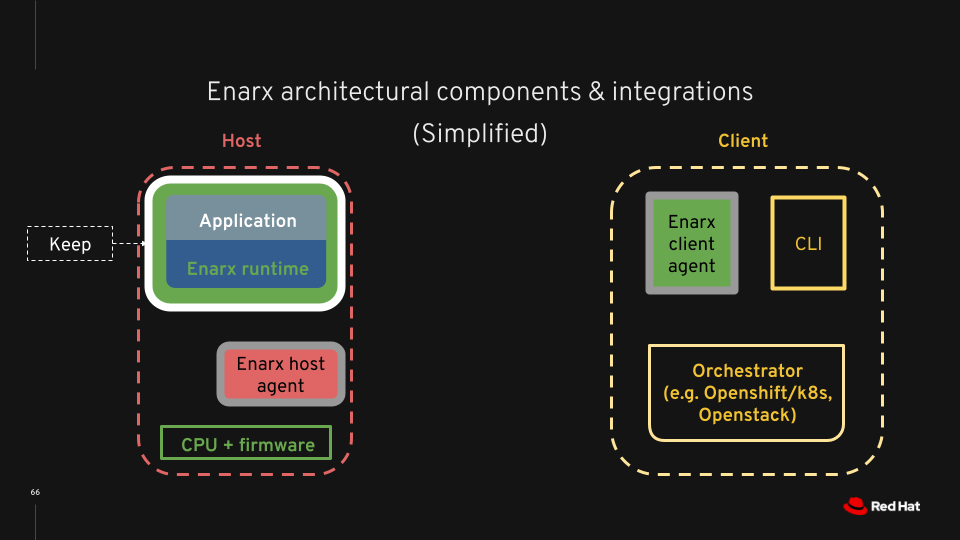
Much of the work that’s been going on has been concentrated in the Enarx runtime component, getting WebAssembly working in SGX and SEV Trusted Execution Environments, working on syscall implementations and attestation. There’s also been quite a lot of work on glue – how we transfer information around the system in a standards-compliant way (we’re using CBOR encoding throughout). The pieces that I’ve been putting together have been the Enarx client agent, the Enarx host agent (or Enarx Keep Manager) and two pieces which aren’t visible in this diagram (but are in the more detailed one below): the Enarx Keep Loader and Enarx Wasm Loader (“App loader” in the detailed view).
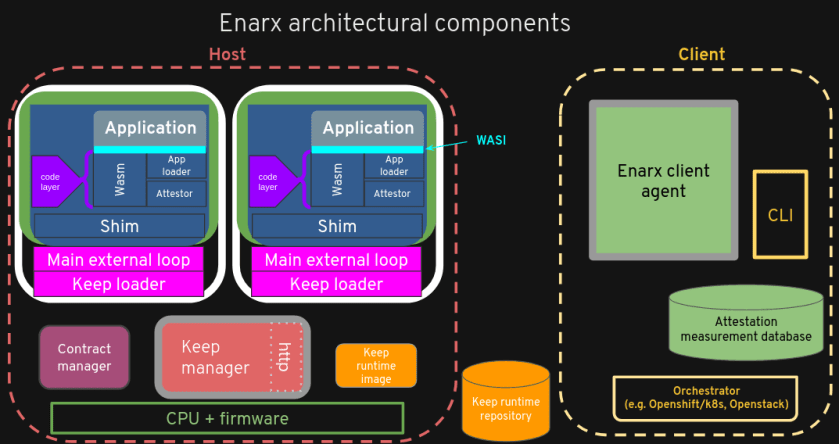
The components
Let’s look at what these components do, and then explain exactly what we’ve achieved. The name in bold refers to the diagram, the name in italics relates to the Rust crate (and, where already merged, the github repository) associated with the component.
- Enarx Client Agent (client) – responsible to talking to the enarx-keepmgr and requesting a Keep. It checks that the Keep is correctly set up and attested and then sends the workload (a WebAssembly package) to the enarx-wasmldr component, using HTTPS with a one-use certificate derived from the attestation process.
- Enarx Keep Manager (enarx-keepmgr) – creates enarx-keepldr components at the request of the client, proxying communications to them from the client as required (for certain attestation flows, for instance). It is untrusted by the client.
- Enarx Keep Loader (enarx-keepldr) – there is an enarx-keepldr per Keep, and it performs the loading of components into the Trusted Execution Environment itself. It sits outside the TEE instance, and is therefore untrusted by the client.
- Enarx App Loader (enarx-wasmldr) – the enarx-wasmldr component resides within the TEE instance, and is therefore has confidentiality and integrity protection from the rest of the host. It receives the WebAssembly (Wasm) workload from the client component and may access secret information provisioned into the Keep during the attestation process.
Here’s the post I made to the Enarx chat #development channel yesterday to announce what we managed to achieve:
- client -> keepmgr: “create sev keep”
- keepmgr launches sev keep via systemd
- client -> keepmgr: “perform attestation, include this private key” (note – private key is encrypted from keepmgr)
- keepmgr -> keepldr: “attestation + private key”
- keepldr creates keep, passes private key to it
- wasmldr creates certificate from private key
- wasmldr waits for workload
- client sends workload of HTTPS to wasmldr
- wasmldr accepts workload over HTTPS
- wasmldr executes workload
WE HAVE A FULLY WORKING END-TO-END DEMO! Thank you everyone
What does this mean? Well, everything works! The client requests a Keep using with an AMD SEV instance, it’s created, attested, listens for an incoming connection over HTTPS, and the client sends the workload, which then executes. The workload was written in Rust and compiled to WebAssembly – it’s a real application, in other words, and not a hand-crafted piece of WebAssembly for the purposes of testing.
What’s next?
There’s lots left to do, including:
- merging all of the code into the main repositories (I was working in a separate set to avoid undue impact on other efforts)
- tidying it to make it more presentable (both what the demo shows and the quality of the code!)
- add SGX support – we hope that we’re closing in on this very soon
- make the various components production-ready (the keepmgr, for instance, doesn’t manage multiple enarx-keepldr components very well yet)
- define the wire protocol fully (somewhere other than in my head)
- document everything!
But most of that’s easy: it’s just engineering. 🙂
We’d love you to become involved. If you’re interested, read some of my articles, visit project home page and repositories, hang out on our chat server or watch some of our videos on YouTube. We really welcome involvement – and not just from engineers, either. Come and have a play!