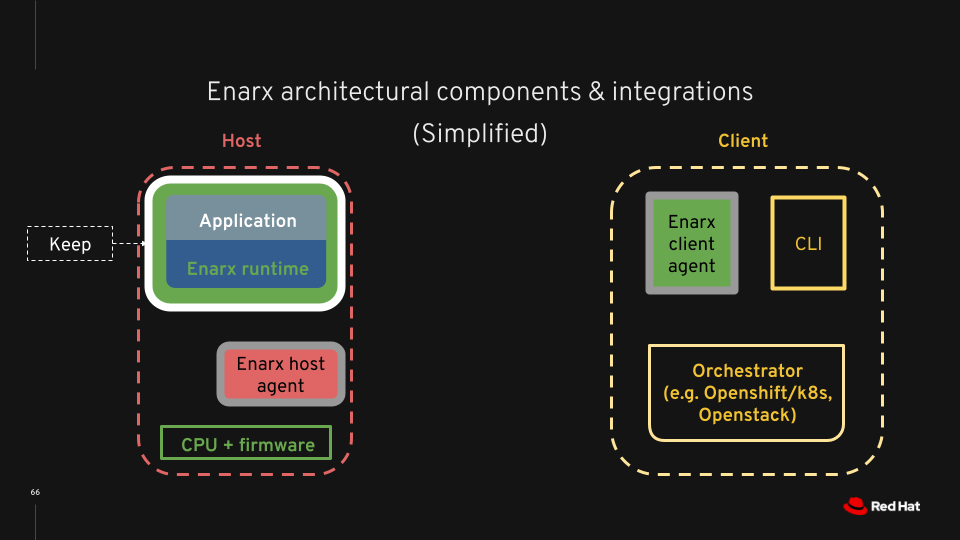
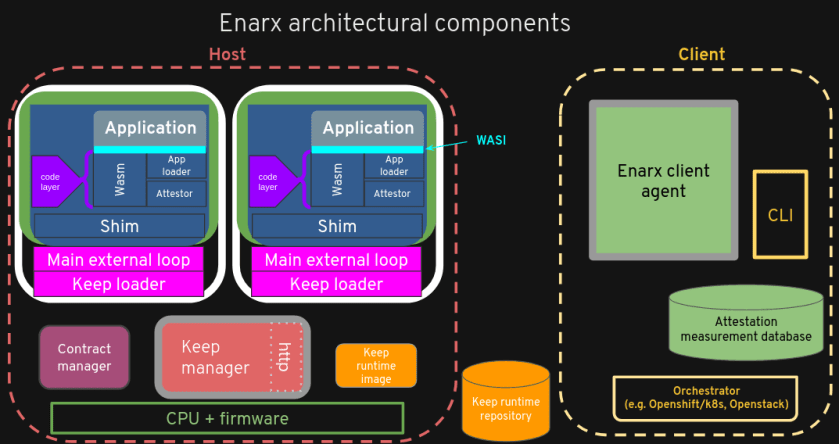
I’m a fairly recent convert to Rust, which I started to learn around the end of April 2020 (when we assumed there would only be the one lockdown, and that Covid-19 would be “over by Christmas” – oh, the youthful folly). But, like many converts, I’m an enthusiastic evangelist. I’m also not a very good Rustacean, truth be told, in that my coding style isn’t great, and I don’t write particularly idiomatic Rust. This is partly, I suspect, because I never really finished learning Rust before diving in and writing quite a lot of code (some of which is coming back to haunt me) and partly because I’m just not that good a programmer.
But I love Rust, and so should you. It’s friendly – well, more friendly than C or C++ – it’s ready for low-level systems tasks – more so than Python – it’s well-structured – more than Perl – and, best of all, it’s completely open source, from the design level up – much more than Java, for instance. Despite my lack of expertise, I noticed a few things which I suspect are common to many Rust enthusiasts and programmers, the first of which was sparked by some exciting recent news.
The word Foundation excites you
For Rust programmers, the word “Foundation” will no longer be associated first and foremost with Isaac Asimov, but with the newly formed Rust Foundation. Microsoft, Huawei, Google, AWS and Mozilla are providing the directors (and presumably most of the initial funding) for the foundation, which will look after all aspects of the language, “heralding Rust’s arrival as an enterprise production-ready technology”, according to the Interim Executive Director, Ashley Williams (on a side note, it’s great to see a woman heading up such a major industry initiative).
The Foundation seems committed to safe-guarding the philosophy of Rust and ensuring that everybody has the opportunity to get involved. Rust is, in many ways, a poster-child example of an open source project. Not that it’s perfect (either the language or the community!), but in that there seem to be sufficient enthusiasts who are dedicated to preserving the high-involvement, low-bar approach to community which I think of as core to the much of open source. I strongly welcome the move, which I think can only help to promote Rust adoption and maturity over the coming years and months.
You get frustrated by news feed references to Rust (the game)
There’s another computer-related thing out there which goes by the name “Rust”, and it’s a “multi-player only survival video game”. It’s newer than Rust the language (having been announced only in 2013 and released in 2018), but I was once searching for Rust-related swag and, coming across it, made the mistake of searching for it. The Interwebs being what they are (thanks, Facebook, Google et al.), this meant that my news feed is now infected with this alternative Rust beast and I now get random updates from their fandom and PR folks. Thisis low-key annoying, but I’m pretty sure that I’m not alone in the Rust (language) community. I strongly suggest that if you do want to find out more about this upstart in the computing world, you use a privacy-improving (I refuse to say “privacy-preserving”) browser such as DuckDuckGo or even Tor to do your research.
The word “unsafe” makes you recoil in horror
Rust (the language, again) does a really good job of helping you do the Right Thing[TM]. Certainly in terms of memory safety, which is a major concern within C and C++ (not because it’s impossible, but because it’s really hard to get right consistently). Dave Herman wrote a post in 2016 on why safety is such a positive attribute of the Rust language: Safety is Rust’s Fireflower. Safety (memory, type safety) may not be sexy, but it’s something that you become used to, and grateful for, as you write more Rust – particularly if you’re involved in any systems programming, which is where Rust often excels.
Now, Rust doesn’t stop you from doing the Wrong Thing[TM], but it does make you make a conscious decision when you wish to go outside the bounds of safety, by making you use the unsafe keyword. This is good not only for you, as it will (hopefully) make you think really, really carefully about what you’re putting in any code block which uses it, but also for anyone reading your code: it’s a trigger word which makes any half-sane Rustacean shiver at least slightly, sit upright in their chair and think: “hmm, what’s going on here? I need to pay special attention”. If you’re lucky, that person person reading your code may be able to think of ways of rewriting your code in such a way that it does make use of Rust’s safety features, or at least reduces the amount of unsafe code that gets committed and released.
You wonder why there’s no emoji for ?; or {:?} or ::<>
Everybody loves (to hate) the turbofish (::<>), but there are other semantic constructs that you see regularly in Rust code, in particular {:?} (for string formatting) and ?; (? is a way of propagating errors up the calling stack, and ; ends the line/block, so you often see them together). They’re so common in Rust code that you just learn to parse them as you go, and they’re also so useful that I sometimes wonder why they’ve not made it into normal conversation, at least as emojis. There are probably others, too: what would be your suggestions? (Please, please no answers from Lisp adherents.)
Clippy is your friend (and not an animated paperclip)
Clippy, the Microsoft animated paperclip, was a “feature” that Office users learned very quickly to hate, and which has become the starting point for many memes. cargo clippy, on the other hand, is one of those amazing cargo commands that should become part of every Rust programmer’s toolkit. Clippy is a language linter and helps improve your code to make it cleaner, tidier, more legible, more idiomatic and generally less embarrassing when you share it with your colleagues or the rest of the world. Cargo has arguably rehabilitated the name “Clippy”, and although it’s not something I’d choose to name one of my kids, I don’t feel a sense of unease whenever I come across the term on the web anymore.